Fingered by DNA 
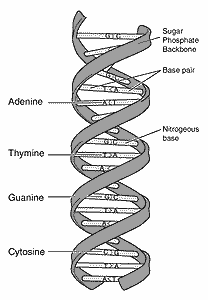
Even more than a finger's print, each person's "DNA fingerprint" is unique. While old-fashioned fingerprints record the wavy, whorled ridges on fingertips, DNA fingerprints record the chemistry of small sections of DNA in chromosomes. A genome -- a complete set of human chromosomes -- is a string of DNA with about 3 billion chemical modules, or bases, divided into roughly 3,000 genes. If you think of the genome as a giant reel of videotape, each gene corresponds to one TV show. The thousands of bases in a gene correspond to thousands of thrilling seconds of comedy or drama, in our analogy.
DNA stores information in a four-letter code: Each base, or nucleotide, is labeled C, G, A or T. Four letters may seem primitive compared to our 26-letter alphabet, or our 10-digit counting system. Still, the DNA in every one of your cells codes for all of the thousands of proteins you need from conception to death.
Each position on the long molecule can store twice as much data as one bit of computer code, and that only improves once you consider multiple locations. While three bits of binary code can store 8 (2 to the third power) unique combinations, three
bases of DNA can record 64 (4 to the fourth power) combos. Three is a magic number, since three adjacent bases specify one amino acid, the building block of proteins. (DNA's entire job is to serve as a pattern for proteins.)
Making sense of nonsense DNA
Having read this far, you're probably expecting a discussion of genes and proteins, but as they snarl on NYPD Blue, "Fugeddaboudit, buddy." DNA fingerprinters ignore the DNA in genes in favor of "junk DNA" between the genes.
(Here's a good place to distinguish DNA fingerprinting from DNA sequencing, the decoding of genetic instructions for humans or other species. DNA fingerprinting is much simpler because it looks only at short strands of DNA, in places where one person will likely vary from another.)
Those places are called "junk DNA," or "filler DNA" or "nonsense DNA." Technically, these "introns" separate the "exons," which serve as protein patterns.
This poorly understood junk is generally considered a heckuva lot less interesting than the DNA that codes for proteins. We like to compare nonsense DNA to the ads that foul up sitcoms, say, or cop shows. Just as most people ignore those ads, most geneticists ignore junk DNA; the Human Genome Project, for example, has spent billions reading the sequence of DNA on genes but largely ignores the nonsense.
But DNA fingerprinters are obsessed with junk.
Here's why. Genes make proteins, but proteins work only when patterned on a good DNA template. So the DNA in genes must stay essentially the same generation after generation. Changes are called mutations, and most mutations are harmful.
Say you had a tissue sample from a 1962 strangling in Boston and decoded the bases in the gene that makes serotonin (a molecule that helps nerve cells communicate). The gene would be almost identical to your own serotonin gene -- or O.J. Simpson's, for that matter.
The reason? Most genes for defective serotonin are (like sitcoms that flame out for being too intelligent in the pilot stage), immediately culled from the gene pool. But the genetic similarity wouldn't make you -- or the juicy guy either -- the Boston strangler, who murdered 11 women. 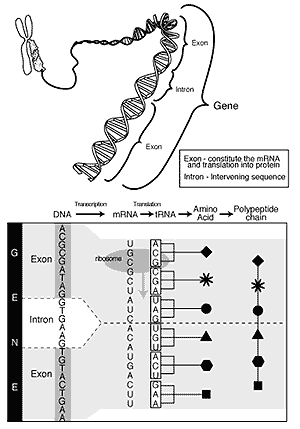
Once was boring enough!
Fortunately, junk DNA is exempt from the need to remain identical. Like an ad on Ally McBeal, it can change, and nobody will notice much.
The characteristic change in junk DNA is called a "repeat." In repeats, short sections are duplicated. In repeats, short sections are duplicated. Like this. Like this.
If a TV ad underwent a repeat, "What_do_you_want_the_Internet_to_be?" would become "What_do_you_want_the_Internet_to_be? What_do_you_want_the_Internet_to_be? What_do_you_want_the_Internet_to_be? What_do_you_want_the_Internet_to_be?"
Terrifying. In Latin, that's called ad nauseum.
In English, it's called boring -- and too familiar -- but who's paying attention?
Similarly, in junk DNA, the sequence "CGGT" might form the repeat "CGGT CGGT CGGT CGGT CGGT CGGT." But since the protein-patterning apparatus ignores junk DNA, the repeat would likely be meaningless.
Unless your game is forensics.
Junk reading
Over the past 15 years or so, it's become ever-easier to analyze repeats in junk DNA -- to turn trash into treasure, so to speak.
In 1984, the English scientist Alec Jeffries invented RFLP (restriction fragment length polymorphism -- we see that hand in the back of the room). The technique used "restriction enzymes" -- chemicals that cut the DNA molecule at specific locations, leaving smaller fragments where specific repeats could be counted.
Using complicated statistics, scientists could compare the genetics of the crime-scene sample and the suspect.
After its successful use in 1986, RFLP gained popularity for identifying tissue samples at a crime scene -- and for proving that a sample did not come from a suspect. But RFLP required more than 200 lab steps, driving technicians nuts and raising costs and chances for error. And it took weeks to carry out -- valuable time during which the police might be investigating the wrong suspect, allowing the trail to grow cold so the real villian could escape.
By about 1995, a much faster, cheaper and better technique entered the picture. STR -- short tandem repeats -- works, as the name implies, with shorter hunks of DNA, and it has become a favorite of forensic and medical labs alike. "It may only take 50 steps, it's much simpler," says Lars Jorgensen, who's used both techniques for paternity testing at the Madison, Wis., office of the American Red Cross.
PCR 'n STR
Say you have an invisibly small gob of DNA -- taken from blood, sweat or tears at a crime scene. Twenty years ago, even had DNA testing been available, that would have been too little DNA. Today, a toaster-sized polymerase chain reaction (PCR) machine can, in a few hours, produce billions of copies of a specific stretch of DNA.
Although PCR has reduced DNA multiplication to about the level of button-pushing, the technology deservedly won the Nobel prize for chemistry. PCR rests on the biological fact that DNA must accuratley copy itself whenever genes are doubled during cell division, and PCR cleverly exploits this ability.
PCR does, however, speed up this process -- and adds a twist called a "primer." This artificial chemical locates a specific stretch of DNA bases and directs that duplication occur in one direction only from that stretch.
DNA has two matching strands, and by placing the right primer on each strand, you can duplicate whatever stretch is between them. For DNA fingerprinting, you simply choose primers so the repeats just described are between them.
The PCR machine heats this strand, disengaging the double helix and producing two sub-strands, each with a string of bases along it. The machine cools slightly, and, with the help of a natural enzyme, each strand gathers bases to form the opposite, or complementary, strand, recreating the full double-helix of DNA.
The system works because DNA bases are choosy: A will join only to T, and C only to G. Because of that, the first cycle turns the original strand into two identical strands. After 28 cycles, one strand becomes 228 strands -- plenty of identical DNA for analytical purposes.
Gelly donut
Since the original strand was chosen to contain only the repeated region, the next step in DNA fingerprinting is to weigh each strand to count the repeats. The weighing takes place in a gel electrophoresis machine, which propels bits of DNA through an electric field. Because each bit receives equal electric force, smaller bits move faster than larger ones. The result is the inscrutable array of dark bands seen above.
We don't want to bog down in the details of gel electrophoresis -- just pronouncing it strains our cerebral capacity -- but you read the gel with a template that tells you how many repeats are present, based on the distance each strand has moved on the gel.
Now things get interesting. The number of short tandem repeats in junk DNA, remember, vary from one person to the next. Databases on STR DNA in unrelated people show expected variations in the overall population, at each of the sites where the DNA is analyzed.
Finding the same number of repeats at one site is suggestive but not conclusive, if, say one person in 10 has the same number of repeats. "One by itself is not specific," says Laber.
But if you find the same odds at two sites, suddenly the odds drop to one in a hundred. If you examined 13 sites specified by the FBI, and found that same one-in-ten odds, the odds that a similar DNA fingerprint would exist in any one person would be one in 10 trillion (1013). DNA fingerprinting typically produces intimidating odds, says Laber. Translated: The odds are that no living person would have that DNA -- except whoever left the tissue sample at the crime scene.
Testing DNA testing
Powerful technologies like DNA fingerprinting often have unforeseen effects. The federal CODIS database, for example, could become something akin to a national warehouse of biological data. And while it cannot, at present, be used to determine who would be susceptible to what genetic illness, will it never be usable for that?
The national DNA database has raised questions. Whose DNA will be entered into the database so a comparison can be made after a crime? All people? All men, since men commit most rapes and murders? Only arrestees? Only convicts? Only certain convicts? How does the Fourth Amendment restriction on search and seizure affect DNA taken from a swab inside the mouth?
The use to of DNA fingerprinting to evaluate innocence for convicts is gaining approval -- if evidence remains available. Richard Dieter, of the Death Penalty Information Center, says the attitude among prosecutors "seems to be evolving. It was resisted as new evidence that should not be allowed. Now the chances are that DNA testing will be allowed."
Because such testing is standard for new trials, he says, "There are not going to be these kinds of cases 20 years from now, cases that look back, because the DNA testing will be done." Today, he adds, there "is a window of cases with people still in prison, on death row" who can be helped -- if they are innocent, and if DNA samples are available.
Death penalty opponents say the Ochoa case highlights a larger problem: False confessions made to avoid the death penalty. Ochoa, for example, confessed despite being innocent and having no criminal record. "The Ochoa case ... serves to highlight the phenomenon of false confessions caused by fear of the death penalty," says Keith Findley, who co-directs the University of Wisconsin-Madison project that helped exonerate the Texas man (see "DNA Testing Clears..." in the bibliography).
DNA fingerprinting may be the best thing for law enforcement since the cop show, but it's not perfect, since it requires biological evidence from the perpetrator. And even if such evidence is present, Dieter says, no amount of technology can "substitute for having a fair trial, for having open files so both sides know the evidence, for having a good lawyer. There are still problems that need to be addressed that DNA does not deal with."
Need more details on DNA fingerprinting?